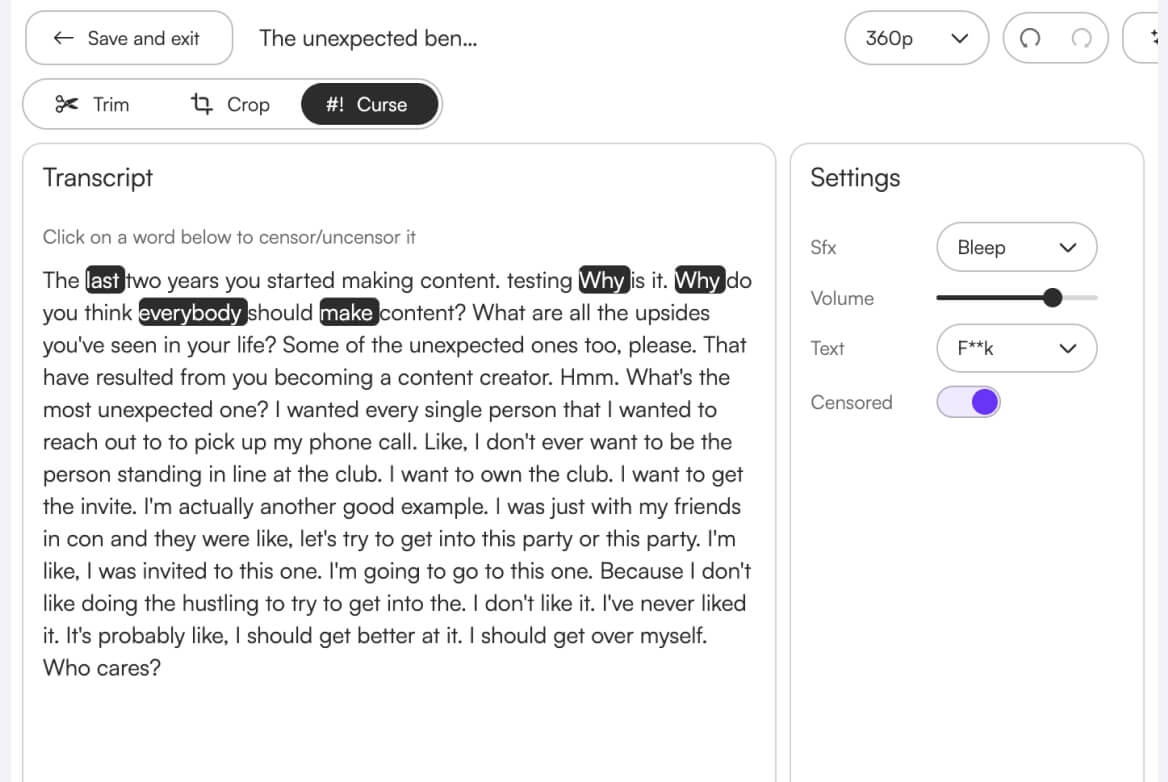
We’ve fixed a bug where censoring a newly added word in the transcript would incorrectly group it with the previous word.
You can now:
This makes fine-grained transcript edits and profanity control far more accurate—especially when cleaning up edge cases after auto-transcription.